
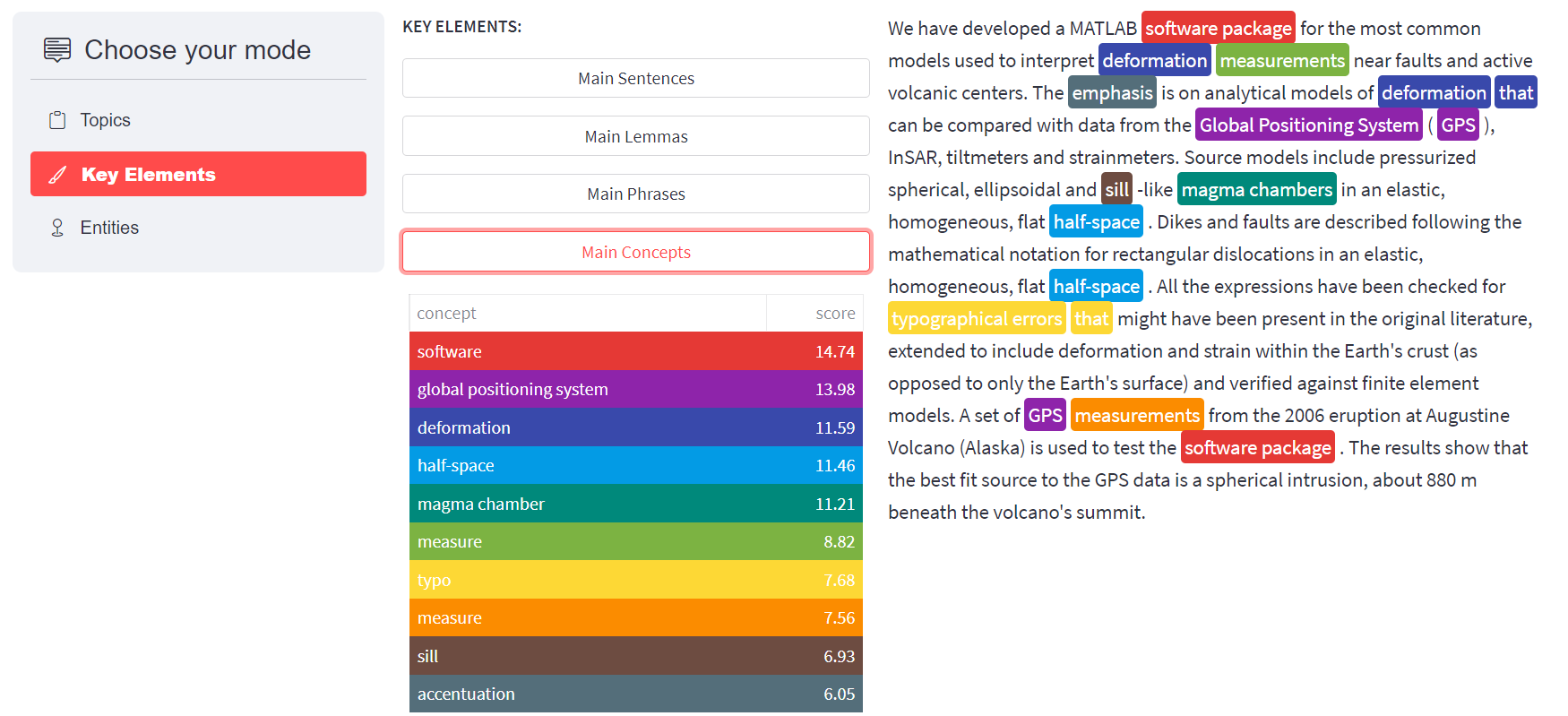
The semantic enrichment process is in charge of generating new metadata out of the text content of files or collections of files, such as Research Objects. This metadata comprise the main concepts found in resources containing text, the main knowledge areas in which these concepts are most frequently used, the main expressions, known in computational linguistics as noun phrases, found in the text, and named entities that are further classified in people, organization and places. The core of the semantic enrichment process is expert.ai software. Expert.ai uses a proprietary semantic network, where words are grouped into concepts with other words sharing the same meaning, and the concepts are related between them by linguistic relations such as hypernyms or hyponyms among many others. Therefore, the semantics of the generated metadata is explicit since the concepts are grounded to the semantic network.
Information retrieval processes, including search engines and
recommendendation systems, can benefit of working with concepts instead of character strings representing words, mainly to
provide a more complete and accurate set of results, and enabling the exploration of file and research object collections by means of facets where the
semantic metadata is available.
The files must be of any of the following types: Word documents, PDF documents, Text files, or PowerPoint Presentations. All these pieces of text are fed into expert.ai to generate the metadata representing their text content. Expert.ai is able to identify the following metadata types in the text:
• Domains
• Main Concepts
• Main Lemmas
• Main Expressions
• Named entities: all the named entities found in the text classified into People, Organizations and
Places.
All these metadata types are added to the response as annotations in a json file. Below an example of how the service can be called and the results that it provides is presented.
curl -X POST -F '[email protected]' https://reliance.expertcustomers.ai/eosc/enrichment

Copied
{
"filename": "dModels.pdf",
"lang": "en",
"domains": {
"mathematics": 17.7,
"geometry": 7.1,
"geology": 26.7
},
"expressions": {
"GPS deformation velocity": 2.6,
"GPS horizontal": 1.8,
"ITRF wgs ellipsoid": 2,
"geology of Augustine volcano": 14,
"volcano Science Center": 1.8,
"inflation of a dippingfinite prolate spheroid": 7.7,
"dMODELS software package im plements": 4.4,
"fault geometry parameter": 2.1,
"Long Valley caldera": 2.4,
"ITRF coordinate": 1.5,
"volcano deformation source": 2.5,
"Princeton University press": 28.2,
"Journal of Geophysical Research": 13.2,
"dMODELS software package": 4.5,
"software availability": 1.3,
"deformation from inflation": 10.8,
"volcano sourceSphere magma chamber McTigue": 3.9,
"fault slip": 2.5,
"MATLAB software package": 2.1,
"volcano deformation": 1.2,
"WorldGeodetic System": 1.8,
"Department of Defense WorldGeodetic system": 1.2,
"software package dMODELS": 2.3
},
"people": {},
"places": {
"Augustine Volcano": 2,
"Augustine": 2,
"New York": 1,
"United States of America": 5,
"Waitt": 1,
"USGMenlo Park": 1,
"January eruption ofAugustine Volcano": 1,
"California": 5,
"Cook Inlet": 1,
"GPS": 1,
"McTigue": 3,
"sourceSphere": 1,
"Sill Fialko": 1,
"Rome": 1,
"Valley": 1,
"Long": 2,
"Alaska": 5,
"Italy": 1,
"Menlo Park": 3
},
"org": {
"Global International Terres": 1,
"Seismological Society of America": 3,
"dMODELS": 4,
"Program": 1,
"Ministry of Defence": 1,
"SAR interferometry": 1,
"Okada": 3,
"Defense Mapping Agency": 3,
"Sapienza University of Rome": 1,
"Journal of Volcanology and Geothermal Research": 5,
"Princeton University": 2,
"Rd": 4,
"ofAnchorage": 1,
"Journal International": 1,
"Science Center": 2,
"ThedMODELS": 1,
"United Statesb Department of Earth Science": 1,
"U.S. Geological Survey": 8,
"National Imagery and Mapping Agency": 4,
"Journal of geophysical research. Biogeosciences": 2
},
"concepts": {
"datum": 5.3,
"data": 5.1,
"software": 14.8,
"geology": 6.6,
"inflation": 6.7,
"chemise": 4.5,
"conduit": 4.9,
"Princeton University": 6.6,
"caldera": 6,
"parametric quantity": 5.9,
"parameter": 7.1,
"deformation": 4.3,
"Alaska": 6.5,
"volcano": 10.8,
"coordinate system": 6.9,
"coordinate": 4.1,
"magma chamber": 6.4,
"fault": 5.3,
"California": 6,
"velocity": 8.1,
"global positioning system": 6.1,
"spheroid": 8.6,
"system": 5.1,
"U.S. Geological Survey": 5.8,
"half-space": 10.5,
"statistics": 9.8
}
}
ROHub uses the Enrichment Service to enrich research objects. You can find some examples of
ROs and the semantic annotations extracted by our service down below:

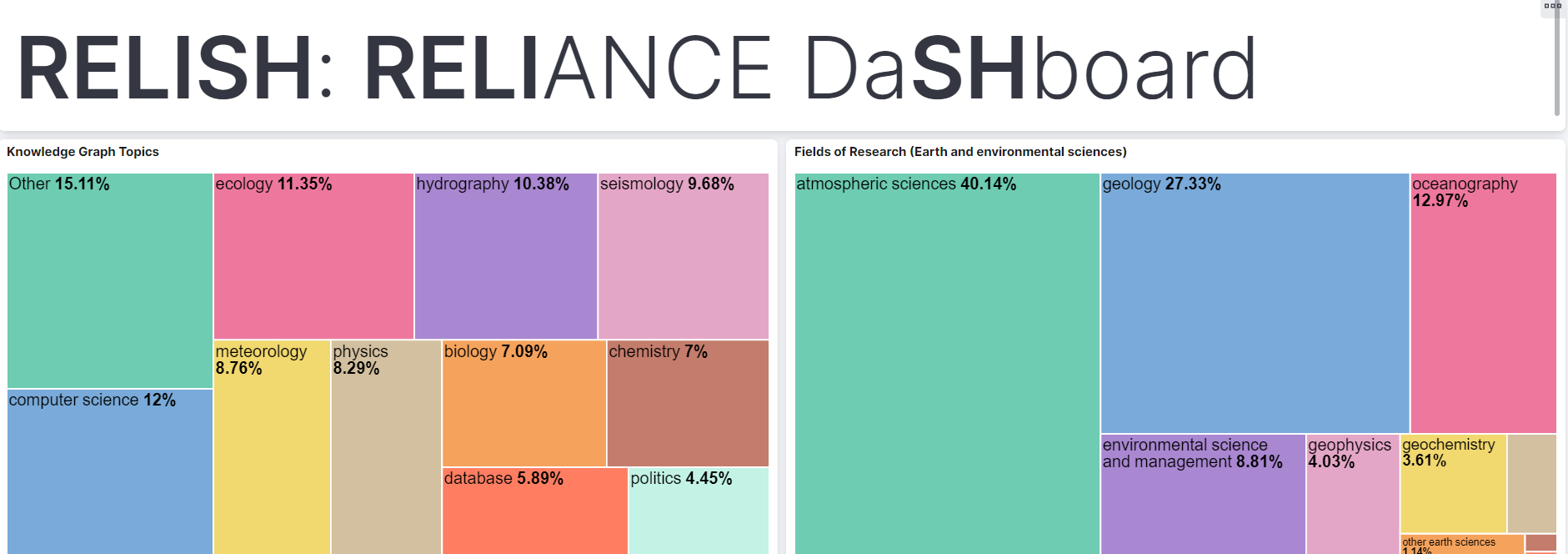
The Search index used by the search service hosts the collection of research objects from the ROHub platform which have been previously enriched. These annotations, added to the original metadata of the research object, are leveraged to produce more accurate results and to provide new facets to explore the research object collection. This index also serves as core for the recommendation api, which returns recommended research objects from this collection. So, the goal of this api is to improve the exploration of the research object collection hosted by ROHub and to allow the users to make facet and semantic searching over them based on their text content.
The Search index follows a scheme which acommodates the metadata obtained from the ROHub platform and the annotations
generated by the enrichment api. It has six different facets: Concepts (most frequent concepts mentioned in the text),
Expressions (Most relevant phrases or collocations found in the text), Domains (fields of knowledge in which the main concepts are most
commonly used), People, Places and Organizations. These facet fields, along with the rest of documents hosted by the index, are updated every
time a research object is created or updated in ROHub. Moreover, each indexed document has attached other related information as the title,
the description or the creator of the Research Object, which can be accessed through the Search API.
The index is built on a Solr version 8.9.0, and can be accessed using the SolrJ API or sending queries right to the service. To do it so, it is necessary to login with an standard user account, which allows to do search queries to the index. More information about how the Solr API works or which type of queries can be sent to this service can be found on the official Solr site. Click on some of their tutorials down below if you want to learn more:
And for more advanced tutorials, click here:
The result of the following query is a json document with the research objects which contains the word "inSAR":
curl --user standard_user:standard_user -H "Content-Type: application/json" https://reliance.expertcustomers.ai/solr/ROHub/select?q=inSAR
Copied
{
"responseHeader": {
"status": 0,
"QTime": 0,
"params": {
"q": "inSAR"
}
},
"response": {
"numFound": 4,
"start": 0,
"numFoundExact": true,
"docs": [{
"id": "https://w3id.org/ro-id/cdcd3c0a-f280-40de-93e6-9a4ba2be6f67",
"title": "Campi Flegrei Caldera (Italy) 2011-2013 deformations from InSAR and GPS and related modelling",
"autocomplete": ["Campi Flegrei Caldera (Italy) 2011-2013 deformations from InSAR and GPS and related modelling",
"SAR interferometry",
"Campi Flegrei Caldera",
"Italy",
"deformations from InSAR",
"reliance-jupyter of the Adam platform",
"related modelling",
"Italy",
"global positioning system",
"deformation"
],
"description": "This Research Object has been created by the reliance-jupyter of the ADAM platform",
"creator": "[email protected]",
"created": "2021-11-10 13:18:11.714467Z",
"source_ro": "https://w3id.org/ro-id/cdcd3c0a-f280-40de-93e6-9a4ba2be6f67",
"sketch": "https://api.rohub.org/api/resources/7a4ded13-3cd6-4eeb-ba21-f86e949a81ae/download/",
"organization": ["SAR interferometry"],
"place": ["Campi Flegrei Caldera",
"Italy"
],
"concepts": ["Italy",
"global positioning system",
"deformation"
],
"content": "Campi Flegrei Caldera (Italy) 2011-2013 deformations from InSAR and GPS and related modelling This Research Object has been created by the reliance-jupyter of the ADAM platform null SAR interferometry Campi Flegrei Caldera Italy deformations from InSAR reliance-jupyter of the Adam platform related modelling net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@c8d094 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f62aa5 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@85ae ",
"compound_terms": ["deformations from InSAR",
"reliance-jupyter of the Adam platform",
"related modelling"
],
"_version_": 1726206744489623552
},
{
"id": "https://w3id.org/ro-id/7749bd2b-72f8-4a29-8565-20a04f419b3a",
"title": "Campi Flegrei Caldera (Italy) 2011-2013 deformations from InSAR and GPS and related modelling",
"autocomplete": ["Campi Flegrei Caldera (Italy) 2011-2013 deformations from InSAR and GPS and related modelling",
"SAR interferometry",
"Campi Flegrei Caldera",
"Italy",
"deformations from InSAR",
"reliance-jupyter of the Adam platform",
"related modelling",
"Italy",
"global positioning system",
"deformation"
],
"description": "This Research Object has been created by the reliance-jupyter of the ADAM platform",
"creator": "[email protected]",
"created": "2021-11-09 21:43:28.116800Z",
"source_ro": "https://w3id.org/ro-id/7749bd2b-72f8-4a29-8565-20a04f419b3a",
"sketch": "https://api.rohub.org/api/resources/3234fc63-64bf-4b38-8950-f334180b48db/download/",
"organization": ["SAR interferometry"],
"place": ["Campi Flegrei Caldera",
"Italy"
],
"concepts": ["Italy",
"global positioning system",
"deformation"
],
"content": "Campi Flegrei Caldera (Italy) 2011-2013 deformations from InSAR and GPS and related modelling This Research Object has been created by the reliance-jupyter of the ADAM platform null SAR interferometry Campi Flegrei Caldera Italy deformations from InSAR reliance-jupyter of the Adam platform related modelling net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@c8d094 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f62aa5 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@85ae ",
"compound_terms": ["deformations from InSAR",
"reliance-jupyter of the Adam platform",
"related modelling"
],
"_version_": 1726206819184934912
},
{
"id": "https://w3id.org/ro-id-dev/ae21f614-ad9d-45ee-b5c5-f6d0fa4841ef",
"title": "Volcano deformation mapping",
"autocomplete": ["Volcano deformation mapping",
"SarScape",
"SBAS InSAR",
"SAR interferometry",
"ground deformation mapping",
"volcano deformation",
"SarScape software interface",
"ground velocity file",
"processing SW SarScape",
"input data Multitemporal InSAR image data",
"GPS site velocity",
"SBAS method",
"InSAR ground deformation",
"processing method",
"line of sight run script",
"velocity file",
"same volcano",
"deformation mapping",
"different volcano",
"deformation",
"mapping",
"velocity",
"global positioning system",
"researcher",
"volcano",
"data",
"input file",
"soil",
"vertical redundancy check",
"script",
"programming interface",
"raster",
"result",
"processing",
"statistics",
"rule",
"remainder",
"data processing",
"validation",
"computer programming",
"telecommunications"
],
"description": "Ground deformation mapping is a typical use case for this VRC. It may be carried out by different researchers on different volcanoes or even on the same volcano",
"creator": "http://rapw3k.livejournal.com/",
"created": "2016-01-22 11:43:56.224000Z",
"source_ro": "https://w3id.org/ro-id-dev/ae21f614-ad9d-45ee-b5c5-f6d0fa4841ef",
"sketch": "https://rohub2020-rohub.apps.paas-dev.psnc.pl/api/resources/db76784d-a19b-46fa-86a8-9e6b7b576c38/download/",
"organization": ["SarScape",
"SBAS InSAR",
"SAR interferometry"
],
"concepts": ["deformation",
"mapping",
"velocity",
"global positioning system",
"researcher",
"volcano",
"data",
"input file",
"soil",
"vertical redundancy check",
"script",
"programming interface",
"raster",
"result",
"processing",
"statistics",
"rule",
"remainder",
"data processing",
"validation"
],
"domains": ["computer programming",
"telecommunications"
],
"content": "Volcano deformation mapping Ground deformation mapping is a typical use case for this VRC. It may be carried out by different researchers on different volcanoes or even on the same volcano null SarScape SBAS InSAR SAR interferometry ground deformation mapping volcano deformation SarScape software interface ground velocity file processing SW SarScape input data Multitemporal InSAR image data GPS site velocity SBAS method InSAR ground deformation processing method line of sight run script velocity file same volcano deformation mapping different volcano net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@8454 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@274f3 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@1ed53 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f62aa5 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@60f1202 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f600a7 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f6887f net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@7528 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f66e44 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@210d5 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@27304 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@3782c net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@4cf9 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@25504 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@f42e3 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@6ea9 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@696f net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@e937 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@65b8880 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f91dab computer programming telecommunications ",
"compound_terms": ["ground deformation mapping",
"volcano deformation",
"SarScape software interface",
"ground velocity file",
"processing SW SarScape",
"input data Multitemporal InSAR image data",
"GPS site velocity",
"SBAS method",
"InSAR ground deformation",
"processing method",
"line of sight run script",
"velocity file",
"same volcano",
"deformation mapping",
"different volcano"
],
"_version_": 1727105872267575296
},
{
"id": "https://w3id.org/ro-id/8b715b0d-b5bb-4d6a-9228-704ec87652f2",
"title": "Sentinel-1 InSAR ground velocity of Etna Volcano, after the big eruption of December 2018",
"autocomplete": ["Sentinel-1 InSAR ground velocity of Etna Volcano, after the big eruption of December 2018",
"SAR interferometry",
"Etna Volcano",
"The Sentinel",
"ground velocity",
"velocity of Etna Volcano",
"ground deformation",
"post-erution pahse of Etan Vocano",
"big eruption",
"ground",
"velocity",
"deformation",
"eruption",
"case",
"comet",
"result"
],
"description": "This Research Object reports the results of a fast InSAR multi-temporal analysis to map ground deformation related to the post-erution pahse of Etan Vocano, after the December 2018 event. The Sentinel-1 SAR data have been processed by using the LiCSBAS method implemented by COMET",
"creator": "[email protected]",
"author": "[email protected]",
"created": "2022-02-16 16:10:01.055517Z",
"source_ro": "https://w3id.org/ro-id/8b715b0d-b5bb-4d6a-9228-704ec87652f2",
"sketch": "https://api.rohub.org/api/resources/762a3696-1d5d-4206-8b53-426e1088ef40/download/",
"organization": ["SAR interferometry"],
"place": ["Etna Volcano",
"The Sentinel"
],
"concepts": ["ground",
"velocity",
"deformation",
"eruption",
"case",
"comet",
"result"
],
"content": "Sentinel-1 InSAR ground velocity of Etna Volcano, after the big eruption of December 2018 This Research Object reports the results of a fast InSAR multi-temporal analysis to map ground deformation related to the post-erution pahse of Etan Vocano, after the December 2018 event. The Sentinel-1 SAR data have been processed by using the LiCSBAS method implemented by COMET [email protected] SAR interferometry Etna Volcano The Sentinel ground velocity velocity of Etna Volcano ground deformation post-erution pahse of Etan Vocano big eruption net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@66b6b97 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@1ed53 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@85ae net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@30bde net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@eba2 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@33b6a net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@25504 ",
"compound_terms": ["ground velocity",
"velocity of Etna Volcano",
"ground deformation",
"post-erution pahse of Etan Vocano",
"big eruption"
],
"_version_": 1726204465236672512
}
]
}
}
The result of the following query is a json document with the research objects which have "Augustine Volcano" as one of
their mentioned places:
curl --user standard_user:standard_user -H "Content-Type: application/json" "https://reliance.expertcustomers.ai/solr/ROHub/select?fq=place:Augustine%20Volcano&q=*:*"
Copied
{
"responseHeader": {
"status": 0,
"QTime": 2,
"params": {
"q": "*:*",
"fq": "place:Augustine Volcano"
}
},
"response": {
"numFound": 12,
"start": 0,
"numFoundExact": true,
"docs": [{
"id": "https://w3id.org/ro-id/8b715b0d-b5bb-4d6a-9228-704ec87652f2",
"title": "Sentinel-1 InSAR ground velocity of Etna Volcano, after the big eruption of December 2018",
"autocomplete": ["Sentinel-1 InSAR ground velocity of Etna Volcano, after the big eruption of December 2018",
"SAR interferometry",
"Etna Volcano",
"The Sentinel",
"ground velocity",
"velocity of Etna Volcano",
"ground deformation",
"post-erution pahse of Etan Vocano",
"big eruption",
"ground",
"velocity",
"deformation",
"eruption",
"case",
"comet",
"result"
],
"description": "This Research Object reports the results of a fast InSAR multi-temporal analysis to map ground deformation related to the post-erution pahse of Etan Vocano, after the December 2018 event. The Sentinel-1 SAR data have been processed by using the LiCSBAS method implemented by COMET",
"creator": "[email protected]",
"author": "[email protected]",
"created": "2022-02-16 16:10:01.055517Z",
"source_ro": "https://w3id.org/ro-id/8b715b0d-b5bb-4d6a-9228-704ec87652f2",
"sketch": "https://api.rohub.org/api/resources/762a3696-1d5d-4206-8b53-426e1088ef40/download/",
"organization": ["SAR interferometry"],
"place": ["Etna Volcano",
"The Sentinel"
],
"concepts": ["ground",
"velocity",
"deformation",
"eruption",
"case",
"comet",
"result"
],
"content": "Sentinel-1 InSAR ground velocity of Etna Volcano, after the big eruption of December 2018 This Research Object reports the results of a fast InSAR multi-temporal analysis to map ground deformation related to the post-erution pahse of Etan Vocano, after the December 2018 event. The Sentinel-1 SAR data have been processed by using the LiCSBAS method implemented by COMET [email protected] SAR interferometry Etna Volcano The Sentinel ground velocity velocity of Etna Volcano ground deformation post-erution pahse of Etan Vocano big eruption net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@66b6b97 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@1ed53 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@85ae net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@30bde net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@eba2 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@33b6a net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@25504 ",
"compound_terms": ["ground velocity",
"velocity of Etna Volcano",
"ground deformation",
"post-erution pahse of Etan Vocano",
"big eruption"
],
"_version_": 1726204465236672512
},
{
"id": "https://w3id.org/ro-id/05256341-c186-4274-a42c-0f7f21cec172",
"title": "Etna Eruption 2021 03 12 Research Object",
"autocomplete": ["Etna Eruption 2021 03 12 Research Object",
"EUMETSAT",
"World Meteorological Organization",
"Etna",
"Trapani",
"height calculation",
"Etna eruption",
"SEVIRI box",
"volcanic column",
"Etna",
"calculation",
"World Meteorological Organization",
"height",
"research",
"sounding",
"column",
"Trapani",
"aim",
"volcanology"
],
"description": "Volcanic Column Top Height calculation using Dark Pixel method in a 19x19 EUMETSAT/SEVIRI box around Etna volcano. Radiosounding provided by WMO in Trapani station",
"creator": "[email protected]",
"created": "2022-02-16 10:34:10.643177Z",
"source_ro": "https://w3id.org/ro-id/05256341-c186-4274-a42c-0f7f21cec172",
"sketch": "https://api.rohub.org/api/resources/e055bc01-239d-4408-af9f-92f6d1200bd6/download/",
"organization": ["EUMETSAT",
"World Meteorological Organization"
],
"place": ["Etna",
"Trapani"
],
"concepts": ["Etna",
"calculation",
"World Meteorological Organization",
"height",
"research",
"sounding",
"column",
"Trapani",
"aim"
],
"domains": ["volcanology"],
"content": "Etna Eruption 2021 03 12 Research Object Volcanic Column Top Height calculation using Dark Pixel method in a 19x19 EUMETSAT/SEVIRI box around Etna volcano. Radiosounding provided by WMO in Trapani station null EUMETSAT World Meteorological Organization Etna Trapani height calculation Etna eruption SEVIRI box volcanic column net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@beee49 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@de7 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f87ad7 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f910d9 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f6861f net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@1011 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f5f3f0 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@bee6bc net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@6e2c volcanology ",
"compound_terms": ["height calculation",
"Etna eruption",
"SEVIRI box",
"volcanic column"
],
"_version_": 1726204467642105856
},
{
"id": "https://w3id.org/ro-id/97f0be52-520a-4ff3-9405-6f51d91ab7ed",
"title": "Etna Eruption 2021 03 12 Research Object",
"autocomplete": ["Etna Eruption 2021 03 12 Research Object",
"EUMETSAT",
"World Meteorological Organization",
"Etna",
"Trapani",
"height calculation",
"Etna eruption",
"SEVIRI box",
"volcanic column",
"Etna",
"calculation",
"World Meteorological Organization",
"height",
"research",
"sounding",
"column",
"Trapani",
"aim",
"volcanology"
],
"description": "Volcanic Column Top Height calculation using Dark Pixel method in a 19x19 EUMETSAT/SEVIRI box around Etna volcano. Radiosounding provided by WMO in Trapani station.",
"creator": "[email protected]",
"created": "2022-02-16 13:58:09.651801Z",
"source_ro": "https://w3id.org/ro-id/97f0be52-520a-4ff3-9405-6f51d91ab7ed",
"organization": ["EUMETSAT",
"World Meteorological Organization"
],
"place": ["Etna",
"Trapani"
],
"concepts": ["Etna",
"calculation",
"World Meteorological Organization",
"height",
"research",
"sounding",
"column",
"Trapani",
"aim"
],
"domains": ["volcanology"],
"content": "Etna Eruption 2021 03 12 Research Object Volcanic Column Top Height calculation using Dark Pixel method in a 19x19 EUMETSAT/SEVIRI box around Etna volcano. Radiosounding provided by WMO in Trapani station. null EUMETSAT World Meteorological Organization Etna Trapani height calculation Etna eruption SEVIRI box volcanic column net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@beee49 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@de7 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f87ad7 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f910d9 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f6861f net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@1011 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f5f3f0 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@bee6bc net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@6e2c volcanology ",
"compound_terms": ["height calculation",
"Etna eruption",
"SEVIRI box",
"volcanic column"
],
"_version_": 1726204466501255168
},
{
"id": "https://w3id.org/ro-id/61bceafe-5b48-4548-8caf-4142153b1b1b",
"title": "Mean ground velocities from ALOS-2 data at Changbaishan volcano (China/North Korea) during 2018-2020",
"autocomplete": ["Mean ground velocities from ALOS-2 data at Changbaishan volcano (China/North Korea) during 2018-2020",
"JAXA",
"Interior",
"China",
"North Korea",
"Changbaishan Volcano",
"Magma Migration",
"Changbaishan",
"Japan",
"ground velocity",
"raster file",
"raw data property",
"property of JAXA",
"data at Changbaishan",
"North Korea",
"velocity",
"China",
"soil",
"raster",
"file",
"aerospace engineering"
],
"description": "This Research Object contains the raster file of the mean ground velocity at the Changbaishan Volcano (China/North Korea) from ALOS-2 satellite data during 2018-2020. Find more on processing and results in the related paper: 'Upward Magma Migration within the Multi-level Plumbing System of the Changbaishan Volcano (China/North Korea) Revealed by the Modeling of 2018-2020 SAR Data' by E. Trasatti, C. Tolomei, L. Wei, G. Ventura. DOI: 10.3389/feart.2021.741287 . Raw data property of JAXA (Japan).",
"creator": "[email protected]",
"created": "2021-12-13 17:49:07.069454Z",
"source_ro": "https://w3id.org/ro-id/61bceafe-5b48-4548-8caf-4142153b1b1b",
"sketch": "https://api.rohub.org/api/resources/17d678c6-4274-4475-9fb0-bc6fc00199ae/download/",
"organization": ["JAXA",
"Interior"
],
"place": ["China",
"North Korea",
"Changbaishan Volcano",
"Magma Migration",
"Changbaishan",
"Japan"
],
"concepts": ["North Korea",
"velocity",
"China",
"soil",
"raster",
"file"
],
"domains": ["aerospace engineering"],
"content": "Mean ground velocities from ALOS-2 data at Changbaishan volcano (China/North Korea) during 2018-2020 This Research Object contains the raster file of the mean ground velocity at the Changbaishan Volcano (China/North Korea) from ALOS-2 satellite data during 2018-2020. Find more on processing and results in the related paper: 'Upward Magma Migration within the Multi-level Plumbing System of the Changbaishan Volcano (China/North Korea) Revealed by the Modeling of 2018-2020 SAR Data' by E. Trasatti, C. Tolomei, L. Wei, G. Ventura. DOI: 10.3389/feart.2021.741287 . Raw data property of JAXA (Japan). null JAXA Interior China North Korea Changbaishan Volcano Magma Migration Changbaishan Japan ground velocity raster file raw data property property of JAXA data at Changbaishan net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@b50679 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@1ed53 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@b424cb net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f66e44 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@4cf9 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@2c3f0 aerospace engineering ",
"compound_terms": ["ground velocity",
"raster file",
"raw data property",
"property of JAXA",
"data at Changbaishan"
],
"_version_": 1726206547669811200
},
{
"id": "https://w3id.org/ro-id/e4c558eb-5b73-4481-aa4e-d511c8a927b6",
"title": "Campi Flegrei",
"autocomplete": ["Campi Flegrei",
"U.S. Geological Survey",
"Journal of Volcanology and Geothermal Research",
"dMODELS",
"Rd",
"National Imagery and Mapping Agency",
"Seismological Society of America",
"Okada",
"Defense Mapping Agency",
"Princeton University",
"Science Center",
"Journal of geophysical research. Biogeosciences",
"Campi Flegrei",
"Global International Terres",
"Program",
"Ministry of Defence",
"SAR interferometry",
"Sapienza University of Rome",
"ofAnchorage",
"Journal International",
"ThedMODELS",
"United States of America",
"California",
"Alaska",
"McTigue",
"Menlo Park",
"Augustine Volcano",
"Augustine",
"Long",
"New York",
"Waitt",
"USGMenlo Park",
"January eruption ofAugustine Volcano",
"Cook Inlet",
"GPS",
"sourceSphere",
"Sill Fialko",
"Rome",
"Valley",
"Italy",
"Campi Flegrei",
"Princeton University press",
"ascii file",
"workflow Ro",
"geology of Augustine volcano",
"Journal of Geophysical Research",
"deformation from inflation",
"source parameter",
"inflation of a dippingfinite prolate spheroid",
"Campi Flegrei case study",
"inversion standard deviations",
"dMODELS software package",
"dMODELS software package im plements",
"volcano sourceSphere magma chamber McTigue",
"GPS deformation velocity",
"volcano deformation source",
"fault slip",
"Long Valley caldera",
"software package dMODELS",
"fault geometry parameter",
"MATLAB software package",
"Campi Flegrei",
"gallo",
"software",
"compressed file",
"Ro",
"volcano",
"half-space",
"statistics",
"American Standard Code for Information Interchange",
"spheroid",
"deformation",
"velocity",
"parameter",
"folder",
"parameter",
"coordinate system",
"inflation",
"geology",
"Princeton University",
"Alaska",
"geology",
"mathematics",
"geometry"
],
"description": "Non cattera il gallo prima che tu mi negarai tre volte",
"creator": "http://everest.psnc.pl/users/vitrom",
"created": "2018-09-18 12:44:45.276000Z",
"source_ro": "https://w3id.org/ro-id/e4c558eb-5b73-4481-aa4e-d511c8a927b6",
"organization": ["U.S. Geological Survey",
"Journal of Volcanology and Geothermal Research",
"dMODELS",
"Rd",
"National Imagery and Mapping Agency",
"Seismological Society of America",
"Okada",
"Defense Mapping Agency",
"Princeton University",
"Science Center",
"Journal of geophysical research. Biogeosciences",
"Campi Flegrei",
"Global International Terres",
"Program",
"Ministry of Defence",
"SAR interferometry",
"Sapienza University of Rome",
"ofAnchorage",
"Journal International",
"ThedMODELS"
],
"place": ["United States of America",
"California",
"Alaska",
"McTigue",
"Menlo Park",
"Augustine Volcano",
"Augustine",
"Long",
"New York",
"Waitt",
"USGMenlo Park",
"January eruption ofAugustine Volcano",
"Cook Inlet",
"GPS",
"sourceSphere",
"Sill Fialko",
"Rome",
"Valley",
"Italy",
"Campi Flegrei"
],
"concepts": ["Campi Flegrei",
"gallo",
"software",
"compressed file",
"Ro",
"volcano",
"half-space",
"statistics",
"American Standard Code for Information Interchange",
"spheroid",
"deformation",
"velocity",
"parameter",
"folder",
"parameter",
"coordinate system",
"inflation",
"geology",
"Princeton University",
"Alaska"
],
"domains": ["geology",
"mathematics",
"geometry"
],
"content": "Campi Flegrei Non cattera il gallo prima che tu mi negarai tre volte null U.S. Geological Survey Journal of Volcanology and Geothermal Research dMODELS Rd National Imagery and Mapping Agency Seismological Society of America Okada Defense Mapping Agency Princeton University Science Center Journal of geophysical research. Biogeosciences Campi Flegrei Global International Terres Program Ministry of Defence SAR interferometry Sapienza University of Rome ofAnchorage Journal International ThedMODELS United States of America California Alaska McTigue Menlo Park Augustine Volcano Augustine Long New York Waitt USGMenlo Park January eruption ofAugustine Volcano Cook Inlet GPS sourceSphere Sill Fialko Rome Valley Italy Campi Flegrei Princeton University press ascii file workflow Ro geology of Augustine volcano Journal of Geophysical Research deformation from inflation source parameter inflation of a dippingfinite prolate spheroid Campi Flegrei case study inversion standard deviations dMODELS software package dMODELS software package im plements volcano sourceSphere magma chamber McTigue GPS deformation velocity volcano deformation source fault slip Long Valley caldera software package dMODELS fault geometry parameter MATLAB software package net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@c8e66f net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@617b24b net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f5fe04 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@1e6be net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@7bf1 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f600a7 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5ffb78e net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@6ea9 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f6038e net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f90f2a net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@85ae net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@1ed53 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@83d7 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@3fe3 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@255d7 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f8b34b net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f66d38 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@1f243 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f63569 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@f1fb4e geology mathematics geometry ",
"compound_terms": ["Princeton University press",
"ascii file",
"workflow Ro",
"geology of Augustine volcano",
"Journal of Geophysical Research",
"deformation from inflation",
"source parameter",
"inflation of a dippingfinite prolate spheroid",
"Campi Flegrei case study",
"inversion standard deviations",
"dMODELS software package",
"dMODELS software package im plements",
"volcano sourceSphere magma chamber McTigue",
"GPS deformation velocity",
"volcano deformation source",
"fault slip",
"Long Valley caldera",
"software package dMODELS",
"fault geometry parameter",
"MATLAB software package"
],
"_version_": 1726206786298445824
},
{
"id": "https://w3id.org/ro-id-dev/ae21f614-ad9d-45ee-b5c5-f6d0fa4841ef",
"title": "Volcano deformation mapping",
"autocomplete": ["Volcano deformation mapping",
"SarScape",
"SBAS InSAR",
"SAR interferometry",
"ground deformation mapping",
"volcano deformation",
"SarScape software interface",
"ground velocity file",
"processing SW SarScape",
"input data Multitemporal InSAR image data",
"GPS site velocity",
"SBAS method",
"InSAR ground deformation",
"processing method",
"line of sight run script",
"velocity file",
"same volcano",
"deformation mapping",
"different volcano",
"deformation",
"mapping",
"velocity",
"global positioning system",
"researcher",
"volcano",
"data",
"input file",
"soil",
"vertical redundancy check",
"script",
"programming interface",
"raster",
"result",
"processing",
"statistics",
"rule",
"remainder",
"data processing",
"validation",
"computer programming",
"telecommunications"
],
"description": "Ground deformation mapping is a typical use case for this VRC. It may be carried out by different researchers on different volcanoes or even on the same volcano",
"creator": "http://rapw3k.livejournal.com/",
"created": "2016-01-22 11:43:56.224000Z",
"source_ro": "https://w3id.org/ro-id-dev/ae21f614-ad9d-45ee-b5c5-f6d0fa4841ef",
"sketch": "https://rohub2020-rohub.apps.paas-dev.psnc.pl/api/resources/db76784d-a19b-46fa-86a8-9e6b7b576c38/download/",
"organization": ["SarScape",
"SBAS InSAR",
"SAR interferometry"
],
"concepts": ["deformation",
"mapping",
"velocity",
"global positioning system",
"researcher",
"volcano",
"data",
"input file",
"soil",
"vertical redundancy check",
"script",
"programming interface",
"raster",
"result",
"processing",
"statistics",
"rule",
"remainder",
"data processing",
"validation"
],
"domains": ["computer programming",
"telecommunications"
],
"content": "Volcano deformation mapping Ground deformation mapping is a typical use case for this VRC. It may be carried out by different researchers on different volcanoes or even on the same volcano null SarScape SBAS InSAR SAR interferometry ground deformation mapping volcano deformation SarScape software interface ground velocity file processing SW SarScape input data Multitemporal InSAR image data GPS site velocity SBAS method InSAR ground deformation processing method line of sight run script velocity file same volcano deformation mapping different volcano net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@8454 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@274f3 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@1ed53 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f62aa5 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@60f1202 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f600a7 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f6887f net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@7528 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f66e44 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@210d5 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@27304 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@3782c net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@4cf9 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@25504 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@f42e3 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@6ea9 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@696f net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@e937 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@65b8880 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f91dab computer programming telecommunications ",
"compound_terms": ["ground deformation mapping",
"volcano deformation",
"SarScape software interface",
"ground velocity file",
"processing SW SarScape",
"input data Multitemporal InSAR image data",
"GPS site velocity",
"SBAS method",
"InSAR ground deformation",
"processing method",
"line of sight run script",
"velocity file",
"same volcano",
"deformation mapping",
"different volcano"
],
"_version_": 1727105872267575296
},
{
"id": "https://w3id.org/ro-id/0938a79e-f5a6-4481-b01a-a82e17f7d51a",
"title": "Surface deformation related to the eruption (22 May 2021) of Nyiragongo Volcano (Dem. Rep. Congo) detected by remote sensing",
"autocomplete": ["Surface deformation related to the eruption (22 May 2021) of Nyiragongo Volcano (Dem. Rep. Congo) detected by remote sensing",
"Nyiragongo Volcano",
"Reliance-Jupyter",
"surface deformation",
"Reliance-Jupyter of the Adam platform",
"VSM code",
"remote sensing",
"modelling of the dyke",
"eruption",
"deformation",
"remote sensing",
"surface",
"computer code",
"Democrat",
"outcome"
],
"description": "This Research Object has been created by the Reliance-Jupyter of the ADAM platform. It contains results from the run of the VSM code, related to the modelling of the dyke feeding the eruption of 22 May 2021 at Nyiragongo Volcano (Dem. Rep. Congo) based on remote sensing data (Sentinel-1).",
"creator": "[email protected]",
"created": "2021-11-10 18:55:24.946015Z",
"source_ro": "https://w3id.org/ro-id/0938a79e-f5a6-4481-b01a-a82e17f7d51a",
"sketch": "https://api.rohub.org/api/resources/4c97c24a-edcd-41ec-9374-6e449d8a6390/download/",
"place": ["Nyiragongo Volcano",
"Reliance-Jupyter"
],
"concepts": ["eruption",
"deformation",
"remote sensing",
"surface",
"computer code",
"Democrat",
"outcome"
],
"content": "Surface deformation related to the eruption (22 May 2021) of Nyiragongo Volcano (Dem. Rep. Congo) detected by remote sensing This Research Object has been created by the Reliance-Jupyter of the ADAM platform. It contains results from the run of the VSM code, related to the modelling of the dyke feeding the eruption of 22 May 2021 at Nyiragongo Volcano (Dem. Rep. Congo) based on remote sensing data (Sentinel-1). null Nyiragongo Volcano Reliance-Jupyter surface deformation Reliance-Jupyter of the Adam platform VSM code remote sensing modelling of the dyke net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@30bde net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@85ae net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f8ed26 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@530e net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@72e5 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@ae9f net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@8349 ",
"compound_terms": ["surface deformation",
"Reliance-Jupyter of the Adam platform",
"VSM code",
"remote sensing",
"modelling of the dyke"
],
"_version_": 1726206738640666624
},
{
"id": "https://w3id.org/ro-id/038179f2-f2dc-4cd6-a8ab-28765fb35950",
"title": "Campi Flegrei 2011-2012 dMODELS",
"autocomplete": ["Campi Flegrei 2011-2012 dMODELS",
"U.S. Geological Survey",
"Journal of Volcanology and Geothermal Research",
"dMODELS",
"Rd",
"National Imagery and Mapping Agency",
"Seismological Society of America",
"Okada",
"Defense Mapping Agency",
"Princeton University",
"Science Center",
"Journal of geophysical research. Biogeosciences",
"Campi Flegrei",
"Global International Terres",
"Program",
"Ministry of Defence",
"SAR interferometry",
"Sapienza University of Rome",
"ofAnchorage",
"Journal International",
"ThedMODELS",
"United States of America",
"California",
"Alaska",
"McTigue",
"Menlo Park",
"Augustine Volcano",
"Augustine",
"Long",
"New York",
"Waitt",
"USGMenlo Park",
"January eruption ofAugustine Volcano",
"Cook Inlet",
"GPS",
"sourceSphere",
"Sill Fialko",
"Rome",
"Valley",
"Italy",
"source parameter",
"Princeton University press",
"ascii file",
"Campi Flegrei case study",
"workflow Ro",
"deformation dMODELS",
"geology of Augustine volcano",
"Journal of Geophysical Research",
"shape of the source",
"folder within the content",
"deformation from inflation",
"inflation of a dippingfinite prolate spheroid",
"inversion standard deviations",
"dMODELS software package",
"dMODELS software package im plements",
"volcano sourceSphere magma chamber McTigue",
"GPS deformation velocity",
"volcano deformation source",
"fault slip",
"Long Valley caldera",
"Ro",
"parameter",
"software",
"deformation",
"compressed file",
"error",
"case study",
"volcano",
"half-space",
"statistics",
"American Standard Code for Information Interchange",
"doc file",
"spheroid",
"folder",
"velocity",
"folder",
"parameter",
"coordinate system",
"inflation",
"geology",
"geology",
"mathematics",
"geometry"
],
"description": "The analytical model of deformation dMODELS was applied to the Campi Flegrei case study for the period 2011-2012. This RO contains the source parameters and the estimated errors committed in modeling the geophysical source by inverting GPS data; the shape of the source is considered as a sphere. More details are available in the 'documents' folder within the 'Content' section (see 'Description dModels_Campi_Flegrei.docx'). ",
"creator": "http://everest.psnc.pl/users/vitrom",
"created": "2018-09-18 12:44:45.276000Z",
"source_ro": "https://w3id.org/ro-id/038179f2-f2dc-4cd6-a8ab-28765fb35950",
"organization": ["U.S. Geological Survey",
"Journal of Volcanology and Geothermal Research",
"dMODELS",
"Rd",
"National Imagery and Mapping Agency",
"Seismological Society of America",
"Okada",
"Defense Mapping Agency",
"Princeton University",
"Science Center",
"Journal of geophysical research. Biogeosciences",
"Campi Flegrei",
"Global International Terres",
"Program",
"Ministry of Defence",
"SAR interferometry",
"Sapienza University of Rome",
"ofAnchorage",
"Journal International",
"ThedMODELS"
],
"place": ["United States of America",
"California",
"Alaska",
"McTigue",
"Menlo Park",
"Augustine Volcano",
"Augustine",
"Long",
"New York",
"Waitt",
"USGMenlo Park",
"January eruption ofAugustine Volcano",
"Cook Inlet",
"GPS",
"sourceSphere",
"Sill Fialko",
"Rome",
"Valley",
"Italy"
],
"concepts": ["Ro",
"parameter",
"software",
"deformation",
"compressed file",
"error",
"case study",
"volcano",
"half-space",
"statistics",
"American Standard Code for Information Interchange",
"doc file",
"spheroid",
"folder",
"velocity",
"folder",
"parameter",
"coordinate system",
"inflation",
"geology"
],
"domains": ["geology",
"mathematics",
"geometry"
],
"content": "Campi Flegrei 2011-2012 dMODELS The analytical model of deformation dMODELS was applied to the Campi Flegrei case study for the period 2011-2012. This RO contains the source parameters and the estimated errors committed in modeling the geophysical source by inverting GPS data; the shape of the source is considered as a sphere. More details are available in the 'documents' folder within the 'Content' section (see 'Description dModels_Campi_Flegrei.docx'). null U.S. Geological Survey Journal of Volcanology and Geothermal Research dMODELS Rd National Imagery and Mapping Agency Seismological Society of America Okada Defense Mapping Agency Princeton University Science Center Journal of geophysical research. Biogeosciences Campi Flegrei Global International Terres Program Ministry of Defence SAR interferometry Sapienza University of Rome ofAnchorage Journal International ThedMODELS United States of America California Alaska McTigue Menlo Park Augustine Volcano Augustine Long New York Waitt USGMenlo Park January eruption ofAugustine Volcano Cook Inlet GPS sourceSphere Sill Fialko Rome Valley Italy source parameter Princeton University press ascii file Campi Flegrei case study workflow Ro deformation dMODELS geology of Augustine volcano Journal of Geophysical Research shape of the source folder within the content deformation from inflation inflation of a dippingfinite prolate spheroid inversion standard deviations dMODELS software package dMODELS software package im plements volcano sourceSphere magma chamber McTigue GPS deformation velocity volcano deformation source fault slip Long Valley caldera net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@7bf1 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@83d7 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f5fe04 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@85ae net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@1e6be net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f6544c net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@236ce net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f600a7 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5ffb78e net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@6ea9 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f6038e net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@1d466 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f90f2a net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@1e14a net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@1ed53 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@3fe3 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@255d7 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f8b34b net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f66d38 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@1f243 geology mathematics geometry ",
"compound_terms": ["source parameter",
"Princeton University press",
"ascii file",
"Campi Flegrei case study",
"workflow Ro",
"deformation dMODELS",
"geology of Augustine volcano",
"Journal of Geophysical Research",
"shape of the source",
"folder within the content",
"deformation from inflation",
"inflation of a dippingfinite prolate spheroid",
"inversion standard deviations",
"dMODELS software package",
"dMODELS software package im plements",
"volcano sourceSphere magma chamber McTigue",
"GPS deformation velocity",
"volcano deformation source",
"fault slip",
"Long Valley caldera"
],
"_version_": 1726206817526087680
},
{
"id": "https://w3id.org/ro-id/604e85da-ed1c-4b2f-8b86-d19a6664ea5d",
"title": "campi_flegrei",
"autocomplete": ["campi_flegrei",
"U.S. Geological Survey",
"Journal of Volcanology and Geothermal Research",
"dMODELS",
"Rd",
"National Imagery and Mapping Agency",
"Seismological Society of America",
"Okada",
"Defense Mapping Agency",
"Princeton University",
"Science Center",
"Journal of geophysical research. Biogeosciences",
"Campi Flegrei",
"Global International Terres",
"Program",
"Ministry of Defence",
"SAR interferometry",
"Sapienza University of Rome",
"ofAnchorage",
"Journal International",
"ThedMODELS",
"United States of America",
"California",
"Alaska",
"McTigue",
"Menlo Park",
"Augustine Volcano",
"Augustine",
"Long",
"New York",
"Waitt",
"USGMenlo Park",
"January eruption ofAugustine Volcano",
"Cook Inlet",
"GPS",
"sourceSphere",
"Sill Fialko",
"Rome",
"Valley",
"Italy",
"Princeton University press",
"ascii file",
"workflow Ro",
"geology of Augustine volcano",
"Journal of Geophysical Research",
"deformation from inflation",
"source parameter",
"inflation of a dippingfinite prolate spheroid",
"Campi Flegrei case study",
"inversion standard deviations",
"dMODELS software package",
"dMODELS software package im plements",
"volcano sourceSphere magma chamber McTigue",
"GPS deformation velocity",
"volcano deformation source",
"fault slip",
"Long Valley caldera",
"software package dMODELS",
"fault geometry parameter",
"MATLAB software package",
"software",
"compressed file",
"Ro",
"volcano",
"half-space",
"statistics",
"American Standard Code for Information Interchange",
"spheroid",
"deformation",
"velocity",
"parameter",
"folder",
"parameter",
"coordinate system",
"inflation",
"geology",
"Princeton University",
"Alaska",
"magma chamber",
"global positioning system",
"geology",
"mathematics",
"geometry"
],
"description": "campi flegrei sono i campi dove sono anche dei volcani",
"creator": "http://everest.psnc.pl/users/vitrom",
"created": "2018-09-18 12:44:45.276000Z",
"source_ro": "https://w3id.org/ro-id/604e85da-ed1c-4b2f-8b86-d19a6664ea5d",
"organization": ["U.S. Geological Survey",
"Journal of Volcanology and Geothermal Research",
"dMODELS",
"Rd",
"National Imagery and Mapping Agency",
"Seismological Society of America",
"Okada",
"Defense Mapping Agency",
"Princeton University",
"Science Center",
"Journal of geophysical research. Biogeosciences",
"Campi Flegrei",
"Global International Terres",
"Program",
"Ministry of Defence",
"SAR interferometry",
"Sapienza University of Rome",
"ofAnchorage",
"Journal International",
"ThedMODELS"
],
"place": ["United States of America",
"California",
"Alaska",
"McTigue",
"Menlo Park",
"Augustine Volcano",
"Augustine",
"Long",
"New York",
"Waitt",
"USGMenlo Park",
"January eruption ofAugustine Volcano",
"Cook Inlet",
"GPS",
"sourceSphere",
"Sill Fialko",
"Rome",
"Valley",
"Italy"
],
"concepts": ["software",
"compressed file",
"Ro",
"volcano",
"half-space",
"statistics",
"American Standard Code for Information Interchange",
"spheroid",
"deformation",
"velocity",
"parameter",
"folder",
"parameter",
"coordinate system",
"inflation",
"geology",
"Princeton University",
"Alaska",
"magma chamber",
"global positioning system"
],
"domains": ["geology",
"mathematics",
"geometry"
],
"content": "campi_flegrei campi flegrei sono i campi dove sono anche dei volcani null U.S. Geological Survey Journal of Volcanology and Geothermal Research dMODELS Rd National Imagery and Mapping Agency Seismological Society of America Okada Defense Mapping Agency Princeton University Science Center Journal of geophysical research. Biogeosciences Campi Flegrei Global International Terres Program Ministry of Defence SAR interferometry Sapienza University of Rome ofAnchorage Journal International ThedMODELS United States of America California Alaska McTigue Menlo Park Augustine Volcano Augustine Long New York Waitt USGMenlo Park January eruption ofAugustine Volcano Cook Inlet GPS sourceSphere Sill Fialko Rome Valley Italy Princeton University press ascii file workflow Ro geology of Augustine volcano Journal of Geophysical Research deformation from inflation source parameter inflation of a dippingfinite prolate spheroid Campi Flegrei case study inversion standard deviations dMODELS software package dMODELS software package im plements volcano sourceSphere magma chamber McTigue GPS deformation velocity volcano deformation source fault slip Long Valley caldera software package dMODELS fault geometry parameter MATLAB software package net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f5fe04 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@1e6be net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@7bf1 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f600a7 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5ffb78e net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@6ea9 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f6038e net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f90f2a net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@85ae net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@1ed53 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@83d7 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@3fe3 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@255d7 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f8b34b net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f66d38 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@1f243 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f63569 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@f1fb4e net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5fd55d9 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f62aa5 geology mathematics geometry ",
"compound_terms": ["Princeton University press",
"ascii file",
"workflow Ro",
"geology of Augustine volcano",
"Journal of Geophysical Research",
"deformation from inflation",
"source parameter",
"inflation of a dippingfinite prolate spheroid",
"Campi Flegrei case study",
"inversion standard deviations",
"dMODELS software package",
"dMODELS software package im plements",
"volcano sourceSphere magma chamber McTigue",
"GPS deformation velocity",
"volcano deformation source",
"fault slip",
"Long Valley caldera",
"software package dMODELS",
"fault geometry parameter",
"MATLAB software package"
],
"_version_": 1726206801915936768
},
{
"id": "https://w3id.org/ro-id/f41ec64c-7588-4437-822b-6fd5aa4be4b4",
"title": "campi_flegrei",
"autocomplete": ["campi_flegrei",
"U.S. Geological Survey",
"Journal of Volcanology and Geothermal Research",
"dMODELS",
"Rd",
"National Imagery and Mapping Agency",
"Seismological Society of America",
"Okada",
"Defense Mapping Agency",
"Princeton University",
"Science Center",
"Journal of geophysical research. Biogeosciences",
"Campi Flegrei",
"Global International Terres",
"Program",
"Ministry of Defence",
"SAR interferometry",
"Sapienza University of Rome",
"ofAnchorage",
"Journal International",
"ThedMODELS",
"United States of America",
"California",
"Alaska",
"McTigue",
"Menlo Park",
"Augustine Volcano",
"Augustine",
"Long",
"New York",
"Waitt",
"USGMenlo Park",
"January eruption ofAugustine Volcano",
"Cook Inlet",
"GPS",
"sourceSphere",
"Sill Fialko",
"Rome",
"Valley",
"Italy",
"Princeton University press",
"ascii file",
"workflow Ro",
"geology of Augustine volcano",
"Journal of Geophysical Research",
"deformation from inflation",
"source parameter",
"inflation of a dippingfinite prolate spheroid",
"Campi Flegrei case study",
"inversion standard deviations",
"dMODELS software package",
"dMODELS software package im plements",
"volcano sourceSphere magma chamber McTigue",
"GPS deformation velocity",
"volcano deformation source",
"fault slip",
"Long Valley caldera",
"software package dMODELS",
"fault geometry parameter",
"MATLAB software package",
"software",
"compressed file",
"Ro",
"volcano",
"half-space",
"statistics",
"American Standard Code for Information Interchange",
"spheroid",
"deformation",
"velocity",
"parameter",
"folder",
"parameter",
"coordinate system",
"inflation",
"geology",
"Princeton University",
"Alaska",
"magma chamber",
"global positioning system",
"geology",
"mathematics",
"geometry"
],
"description": "campi flegrei sono i campi dove sono anche dei volcani",
"creator": "http://everest.psnc.pl/users/vitrom",
"created": "2018-09-18 12:44:45.276000Z",
"source_ro": "https://w3id.org/ro-id/f41ec64c-7588-4437-822b-6fd5aa4be4b4",
"organization": ["U.S. Geological Survey",
"Journal of Volcanology and Geothermal Research",
"dMODELS",
"Rd",
"National Imagery and Mapping Agency",
"Seismological Society of America",
"Okada",
"Defense Mapping Agency",
"Princeton University",
"Science Center",
"Journal of geophysical research. Biogeosciences",
"Campi Flegrei",
"Global International Terres",
"Program",
"Ministry of Defence",
"SAR interferometry",
"Sapienza University of Rome",
"ofAnchorage",
"Journal International",
"ThedMODELS"
],
"place": ["United States of America",
"California",
"Alaska",
"McTigue",
"Menlo Park",
"Augustine Volcano",
"Augustine",
"Long",
"New York",
"Waitt",
"USGMenlo Park",
"January eruption ofAugustine Volcano",
"Cook Inlet",
"GPS",
"sourceSphere",
"Sill Fialko",
"Rome",
"Valley",
"Italy"
],
"concepts": ["software",
"compressed file",
"Ro",
"volcano",
"half-space",
"statistics",
"American Standard Code for Information Interchange",
"spheroid",
"deformation",
"velocity",
"parameter",
"folder",
"parameter",
"coordinate system",
"inflation",
"geology",
"Princeton University",
"Alaska",
"magma chamber",
"global positioning system"
],
"domains": ["geology",
"mathematics",
"geometry"
],
"content": "campi_flegrei campi flegrei sono i campi dove sono anche dei volcani null U.S. Geological Survey Journal of Volcanology and Geothermal Research dMODELS Rd National Imagery and Mapping Agency Seismological Society of America Okada Defense Mapping Agency Princeton University Science Center Journal of geophysical research. Biogeosciences Campi Flegrei Global International Terres Program Ministry of Defence SAR interferometry Sapienza University of Rome ofAnchorage Journal International ThedMODELS United States of America California Alaska McTigue Menlo Park Augustine Volcano Augustine Long New York Waitt USGMenlo Park January eruption ofAugustine Volcano Cook Inlet GPS sourceSphere Sill Fialko Rome Valley Italy Princeton University press ascii file workflow Ro geology of Augustine volcano Journal of Geophysical Research deformation from inflation source parameter inflation of a dippingfinite prolate spheroid Campi Flegrei case study inversion standard deviations dMODELS software package dMODELS software package im plements volcano sourceSphere magma chamber McTigue GPS deformation velocity volcano deformation source fault slip Long Valley caldera software package dMODELS fault geometry parameter MATLAB software package net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f5fe04 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@1e6be net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@7bf1 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f600a7 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5ffb78e net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@6ea9 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f6038e net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f90f2a net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@85ae net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@1ed53 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@83d7 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@3fe3 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@255d7 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f8b34b net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f66d38 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@1f243 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f63569 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@f1fb4e net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5fd55d9 net.expertsystem.everest.new_enricher.processor.CustomizedSyncon@5f62aa5 geology mathematics geometry ",
"compound_terms": ["Princeton University press",
"ascii file",
"workflow Ro",
"geology of Augustine volcano",
"Journal of Geophysical Research",
"deformation from inflation",
"source parameter",
"inflation of a dippingfinite prolate spheroid",
"Campi Flegrei case study",
"inversion standard deviations",
"dMODELS software package",
"dMODELS software package im plements",
"volcano sourceSphere magma chamber McTigue",
"GPS deformation velocity",
"volcano deformation source",
"fault slip",
"Long Valley caldera",
"software package dMODELS",
"fault geometry parameter",
"MATLAB software package"
],
"_version_": 1726206809734119424
}
]
}
}

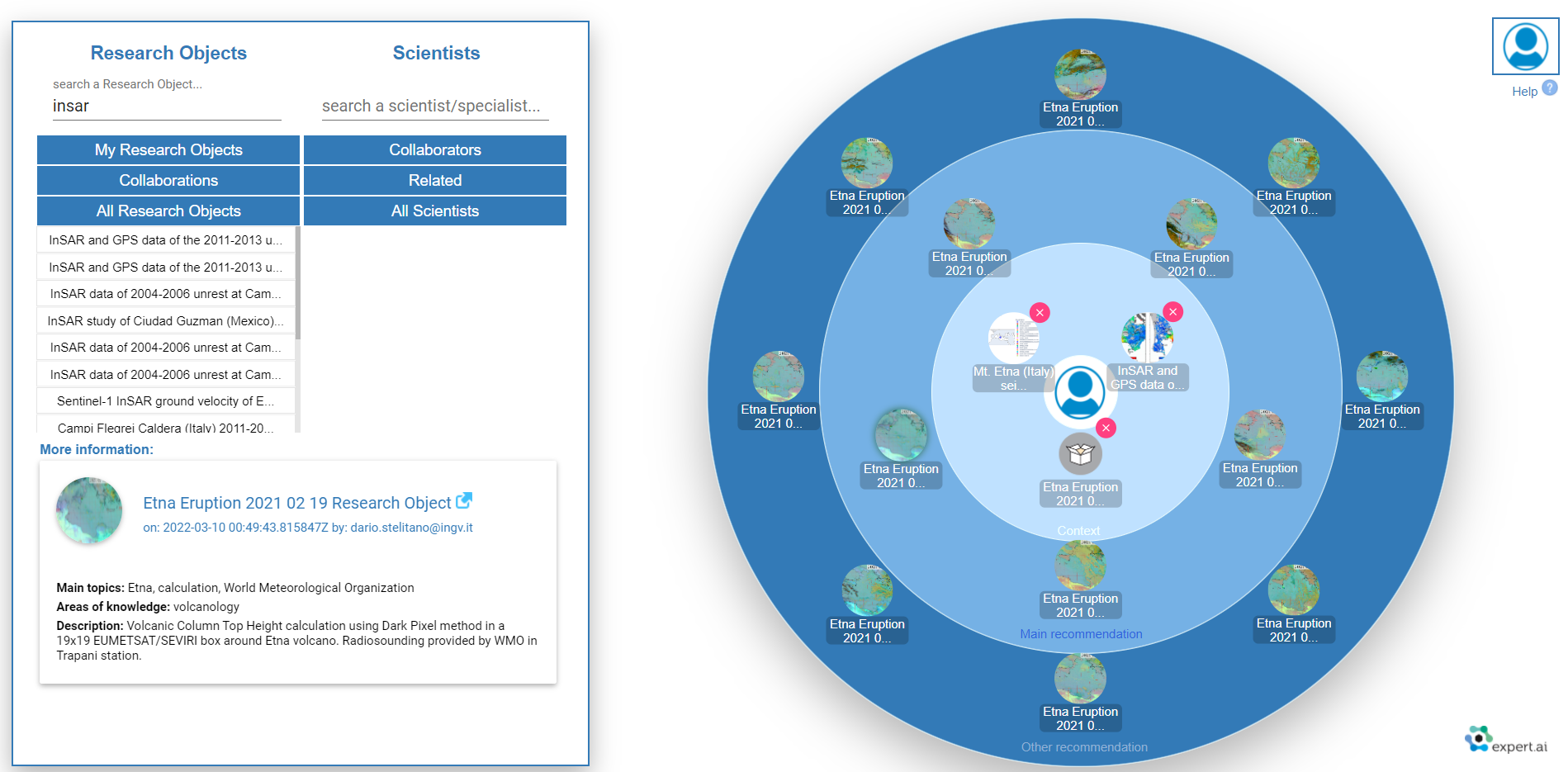
The recommendation system suggests research objects that might be of interest according to user’s research interests. The recommendation system follows a content-based approach in the sense that it compares the research object content with the user interest to draw the list of recommended items. This comparison is based on the annotations added by the semantic enrichment process. The user interests are identified from the top concepts in the user’s research objects. These concepts are then compared with the concepts that annotate the research objects in the whole collection. The user interest can be increased by i) adding specific research objects from other users or ii) adding a different scientist. In the former case the main concepts of the research object are added to the user’s interests and in the latter case the scientist interests are added to the user’s interests. The recommendation system has a rest API and a web user interface called Collaboration Spheres.
The recommendation service rest api accepts post requests and returns a json document with the list of research objects that make up the recommendation. The service is currently deployed in: http://reliance.expertcustomers.ai/spheresbackend/services/jsonservices/api. To include research objects or scientist in the recommendation context the service accepts a json document of the form {“ros”:[“uri-1”,...], “scientists”:[“uri-2”,...]} where the element “ros” is an array containing the list of uris corresponding to the research objects that will be added to the recommendation context and the element scientist is an array containing the list of uris corresponding to the users that will be added to the recommendation context. To be consistent with definition of context in the collaboration spheres a maximum of three uris, either research objects, users or a combination of both, can be added to the recommendation context. Below an example of how the service can be call and the results that it provides is presented.
curl -d '{"ros": ["https://w3id.org/ro-id/038179f2-f2dc-4cd6-a8ab-28765fb35950"],
"scientists":[]}' -H "Content-Type: application/json" -X POST
https://reliance.expertcustomers.ai/spheresbackend/services/jsonservices/api
Copied
{
"recommendation":[
"https://w3id.org/ro-id/604e85da-ed1c-4b2f-8b86-d19a6664ea5d",
"https://w3id.org/ro-id/f41ec64c-7588-4437-822b-6fd5aa4be4b4",
"https://w3id.org/ro-id/e4c558eb-5b73-4481-aa4e-d511c8a927b6",
"https://w3id.org/ro-id/8b715b0d-b5bb-4d6a-9228-704ec87652f2",
"https://w3id.org/ro-id-dev/ae21f614-ad9d-45ee-b5c5-f6d0fa4841ef"
"https://w3id.org/ro-id/0938a79e-f5a6-4481-b01a-a82e17f7d51a"
"https://w3id.org/ro-id/45841548-0362-4aea-80f2-ea71d81a691f"
"https://w3id.org/ro-id/53aa90bf-c593-4e6d-923f-d4711ac4b0e1"
"https://w3id.org/ro-id/b647ed99-fe39-4f6b-bf77-e279d0fdbc50"
"https://w3id.org/ro-id/88a49354-83e8-4da9-a33d-43ae47af938f"
"https://w3id.org/ro-id/4c1cf103-1d85-4acc-bd30-8d8ab8c33d4a"
"https://w3id.org/ro-id/2291348b-bd27-49c4-a515-ab86622c8f84"
]
}

We understand as a scientific claim a statement that can be verified within the scientific literature. It can be an assertion about a specific scientific subject such as “The life cycle of ferns is characterized by two phases: gametophyte and sporophyte”, and it should be verifiable using a reliable and contrasted source. Our goal is then to use claims to connect research objects and scientific publications. The claim analysis pipeline extracts, compares, and connects claims between research objects and scholarly communications in an external scientific repository. The input of this pipeline is the description of a research object from ROHub, and the output is one or more pairs of claims: one claim from the research object and another from the database.
curl -d 'Coronavirus disease 2019 (COVID-19), first reported in Wuhan, the capital of Hubei, China, has been associated to a novel coronavirus, the severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). In March 2020, the World Health Organization declared the SARS-CoV-2 infection a global pandemic. Soon after, the number of cases soared dramatically, spreading across China and worldwide. Italy has had 12,462 confirmed cases according to the Italian National Institute of Health (ISS) as of March 11, and after the 'lockdown' of the entire territory, by May 4, 209,254 cases of COVID-19 and 26,892 associated deaths have been reported. We performed a review to describe, in particular, the origin and the diffusion of COVID-19 in Italy, underlying how the geographical circulation has been heterogeneous and the importance of pathophysiology in the involvement of cardiovascular and neurological clinical manifestations. ' -H "Content-Type: text/plain" -X POST
https://reliance.expertcustomers.ai/extended/claim_analysis
Copied
[
{
"claim":"In March 2020, the World Health Organization declared the SARS-CoV-2 infection a global pandemic"
"verified_claim":[
{
"docno":"21422b462af0ee4705c2ea2e1bc169ed_s0",
"extraction_score":28.12066078186035,
"similarity_score":0.8562994,
"verified_claim":"The novel SARS-CoV-2 outbreak was declared as pandemic by the World Health Organization (WHO) on March 11, 2020.\n"
},
{
"docno":"7562c69833eedef2af3977365ff88711_s1",
"extraction_score":27.13343620300293,
"similarity_score":0.80039823,
"verified_claim":"This cluster quickly spread across the globe and led the World Health Organization (WHO) to declare severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) a pandemic on March 11, 2020.\n"
},
{
"docno":"de1e305d3bc8629c48678cf9b6050b73_s0",
"extraction_score":27.083131790161133,
"similarity_score":0.70187604,
"verified_claim":"Following the emergence of the severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) responsible for COVID-19 in December 2019 in Wuhan (China) and its spread to the rest of the world, the World Health Organization declared a global pandemic in March 2020.\n"
}
}
]
This service extracts the main challenge and the main proposal given the title and the description of a research object. To achieve this, we fine-tuned a language model to classify a sentence as challenge, solution, or none, using a dataset containing texts from an innovation management platform12 annotated with problems and solutions. The dataset13 was annotated by a group of 7 annotators, has a total of 300 texts, and a subset of 20 texts were annotated by all the annotators so that the inter-rater agreement could be calculated as quality metric of the annotation process.
curl -d '{"title": "Further to the Left: Stress-Induced Increase of Spatial Pseudoneglect During the COVID-19 Lockdown", "description": "Background The measures taken to contain the coronavirus disease 2019 (COVID-19) pandemic, such as the lockdown in Italy, do impact psychological health; yet less is known about their effect on cognitive functioning..."} ' -H "Content-Type: application/json" -X POST https://reliance.expertcustomers.ai/extended/csextractor
Copied
{
"error": null,
"results":{
"challenges":[
{
"end":217,
"start":0,
"text":"Background The measures taken to contain the coronavirus disease 2019 (COVID-19) pandemic, such as the lockdown in Italy, do impact psychological health; yet, less is known about their effect on cognitive functioning.",
}
],
"solutions":[
{
"end":710,
"start":467,
"text":"The aim of the present study was to investigate the possible effects and impact of the COVID-19 pandemic on spatial cognition tasks, particularly those concerning spatial exploration, and the physiological leftward bias known as pseudoneglect.",
}
]
}
}
This service calculates the novelty score of a research object. If a research object is similar to an existing research work (in the collection of research objects or in the publications), the novelty score would be very low and vice versa. The range of similarities is between 0 and 1, and consequently the range of the novelty score is between 0 and 100.
curl -d '{"id": "https://w3id.org/ro-id/6bc62582-2f11-4983-a51c-0af32459eca6"} ' -H "Content-Type: application/json" -X POST https://reliance.expertcustomers.ai/extended/novelty_calculation
Copied
{
"id":"https://w3id.org/ro-id/6bc62582-2f11-4983-a51c-0af32459eca6",
"noveltyScore":40.884602157643,
"similarROs":[
{
"id":"https://w3id.org/ro-id/94486a7f-e046-461f-bbb9-334ec7b57040",
"similarityScore":0.5896301393569083,
"title":"Tree crown delineation using detectreeRGB (Jupyter Notebook) published in the Environmental Data Science book",
"description":"The research object refers to the Tree crown delineation using detectreeRGB notebook published in the Environmental Data Science book.",
"sharedTerminology":{
"concepts":[
"research",
],
"description":[
"The research object refers to the Tree crown delineation using detectreeRGB notebook published in the",
],
"title":[
"Tree crown delineation using detectreeRGB (Jupyter Notebook) published in the Environmental Data Science",
"book
]
}
}, ...
],
"similarPublications":[{...}]
}
This service helps users to better understand the content of a research object by challenging them to test their understanding and providing answers to the proposed questions. Starting with the research object id we retrieve the title and description from the elastic search index. Then this text is used to generate the questions and the answers, by calling the question generation (QG) and question answering (QA) modules. All the questions and answers are finally returned to the user.
curl -d '{"id": "https://w3id.org/ro-id/9bf840e3-7a39-41fc-be39-7eed9dc294db"} ' -H "Content-Type: application/json" -X POST https://reliance.expertcustomers.ai/extended/question_generation
Copied
{
"id":"https://w3id.org/ro-id/9bf840e3-7a39-41fc-be39-7eed9dc294db",
"title":"POPANE DATASET - Psychophysiology Of Positive And Negative Emotions",
"description":"Subjective experience along with physiological activity are fundamental components of emotional responding…",
"questions":[
{
"question":"What is POPANE DATASET?",
"score":0.614469485935974,
"answer":"Psychophysiology Of Positive And Negative Emotions",
"answer_score":0.7650960683822632,
},
{
"question":"What is the largest, consistent psychophysiological dataset on emotions ever collected?",
"score":0.7484205365180969,
"answer":"POPANE",
"answer_score":0.3542005717754364,
}
]
}
Learn how to invoke our APIs with the Jupyter Notebook we have released in EGI.
It is available under datahub/Reliance/Text_Mining_Tutorial/
